Experimentation over capabilities
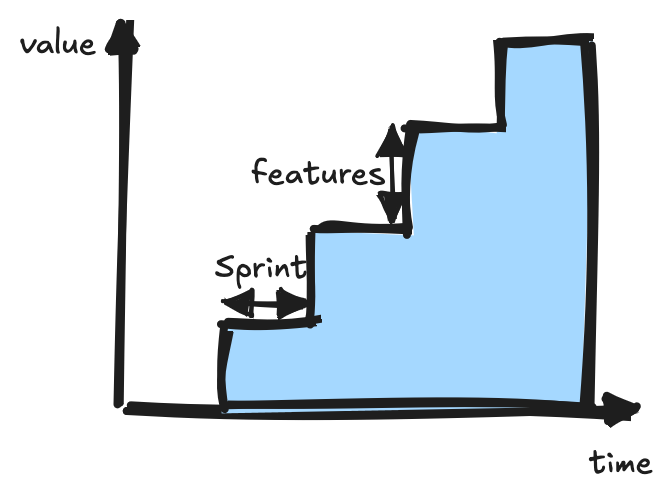 In traditional software engineering, we create customer value by working on small, focused features delivered frequently. When building products where generative AI is a key component, I’ve noticed organizations adopting the term “capability” with similar intentions.
In traditional software engineering, we create customer value by working on small, focused features delivered frequently. When building products where generative AI is a key component, I’ve noticed organizations adopting the term “capability” with similar intentions.
A capability encompasses both features (functionality with clear specifications, designs, and implementation) and evaluations that must pass reliably (test scenarios for LLM-based applications).
The challenge is that it’s inherently difficult for a small team to guarantee eval results within a sprint timeline. LLM-based systems have too many unknowns that need to be resolved via an iterative process also known as context engineering. Teams need domain expertise and good judgment to encode their wisdom into their LLM systems, then rigorously measure and tune based on test scenarios to improve what goes into the context.
When teams face pressure to pass specific scenarios by sprint’s end, they often build subpar products. Instead of creating flexible implementations that generalize well, they over-tune system prompts or artificially constrain tool specifications to guarantee successful outcomes on a narrow set of tests.
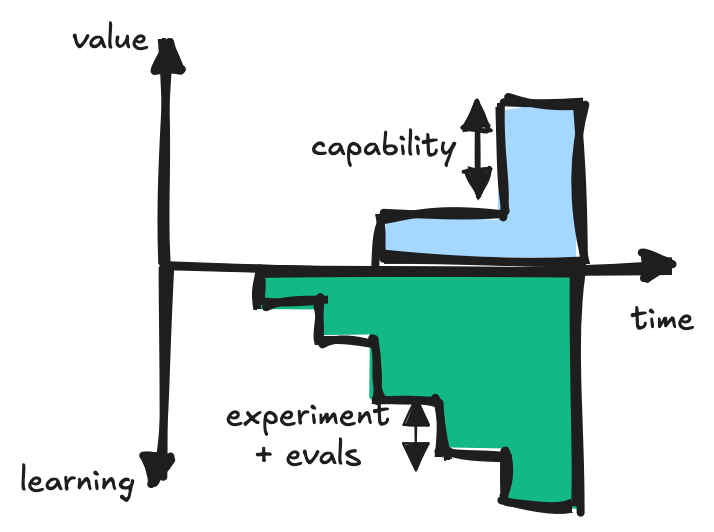 Rather than expecting guaranteed capabilities as sprint outputs, teams building LLM-based products should focus on (i) defining experiments and (ii) growing their evaluation test suites.
Rather than expecting guaranteed capabilities as sprint outputs, teams building LLM-based products should focus on (i) defining experiments and (ii) growing their evaluation test suites.
Before each sprint, teams should consult within themselves and other domain experts to:
- Propose an experiment for addressing the evals (divide and conquering a multi-agent architecture, agent roles, tool specifications)
- Propose additional realistic eval scenarios that test new potential failure modes
At sprint’s end, teams report on eval metrics such as pass rates (pass@1, pass@k, and pass^k), cost, latency, and provide an error analysis report explaining where the system falls short. This analysis then informs the next set of experiments to address those gaps.